Red-Black Trees | 12.22.2016
The latest system I wrote for my game engine project is my own Red-Black trees. This served both to create a powerful and useful new tool for my engine and as a great opportunity to learn about data structures.
Red-Black trees are a form of balanced binary tree. A binary tree is a form of linked list where linked nodes are sorted based on the value of a numerical item they hold. An example of a binary tree is shown here:
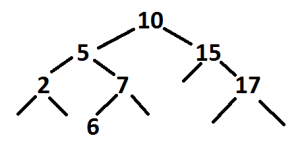
Every number in this tree represents a node, which stores the number shown and links to two other nodes. When a new node is inserted into the tree it starts at the top node, 10. If the number in the new node is larger than the top node it is passed to the right, if it’s smaller it’s passed to the left. This process is repeated at each node until the new node gets to an empty spot where is then stored in the tree.
If a 16 were inserted into the above tree it would be passed right to 15 from 10 (16>10), then right from 15 to 17 (16>15) then left from 17 to the empty spot (16<17).
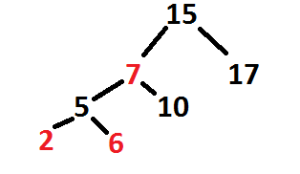
When nodes are inserted in this pattern it is fast to search for them in the tree. Rather than just checking each number until finding the target, the tree can be searched in the same pattern as nodes are inserted (eg. To find 7 the program would check (7<10) -> go left to 5, (7>5) -> go right to find 7). Because of this sorting, the majority of the nodes can be eliminated from the search without being checked.
This method is much faster and scales much better to large data sets, than simply iterating through an entire array as long as the tree is relatively “balanced”. A tree is more “balanced” the more evenly the nodes are distributed among the branches. The previous example tree in the most unbalanced state would be:
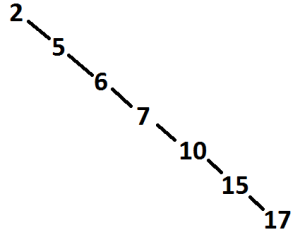
This tree contains all the same data and follows the same rules as the example tree but searching for the data is the same as searching for the data in an array because the target number is always to the right so effectively the search is just iterating over the numbers. Each step of the search only eliminates one node from the search until it finds the right node.
This is where the Red-Black aspect is introduced. Red-Black is an algorithm for balancing the tree as nodes are inserted.
The Red-Black algorithm follows a few simple rules:
- Each node is labeled either red or black
- The root node is black
- If a node is red, it’s child nodes are black
- NULL nodes with no number are black
- Every path from the root node to a bottom node has the same number of black nodes (equal “black height”)
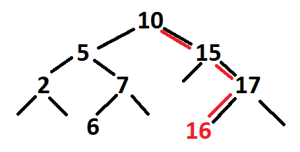
The tree above is an example of a red black tree. All nodes are red or black, the root 15 is black, all red nodes have only black children and each path from 15 to the bottom has an equal black height of 2 (eg. 15 and 17, 15 and 10, 15 and 5).
When a new node is inserted it always starts as red, and is inserted the same way it normally is in an unbalanced binary tree.
Once it gets to the bottom different cases can occur and are resolved to restore the red black rules. In the process of doing this the tree becomes balanced.
The restoration functions make use of changing the color of nodes and what are called “rotations”. A rotation operation takes a sub-tree and rotates the root node left or right. This does not violate the binary tree rules. A combination of these operations can restore the tree from any case to a balanced state.

The example above shows a Red-Black restore operation including a right rotation on 15
There are four possible cases that can occur after an insert.
The first is that the new node ends up as the child of a black node. No rules will be violated in this case and no corrections are needed.
The second is that the new node is the child of a red parent and has a red uncle node. This case can be seen in the 1st stage of the above image (2 is the red parent, 6 is the red uncle). In this case the color of the parent, uncle and grandparent nodes are swapped.
The third case is that the new node has a red parent, a black uncle, and is the left child of a left child or is the right child of a right child. This case can be seen in the 2nd stage of the above image (7 is a red parent, 10 is a black uncle. 7 is the left child of 10 and 5 is the left child of 7). In this case the new node’s grandparent is rotated away from the new node (rotate right in the left-left case, or left in the right-right case). Then the color of the grand parent and parent node are swapped.
The fourth case it that the new node has a red parent, a black uncle and is the left child of a right child or the right child of a left child. In this case the parent is rotated away from the child. This will create case 3 which is resolved as above.

The above example shows a restore using cases 4 and 3.
Performing these operations keeps the tree mostly balanced, keeping search times short.
To demonstrate the improvement in search time and scalability I timed searches in my red-black trees and in standard arrays of the same number of elements to compare. I collected the data by timing one million search operations for random items in an array and tree of the same size. I then divided by the number of searches and plotted the results.
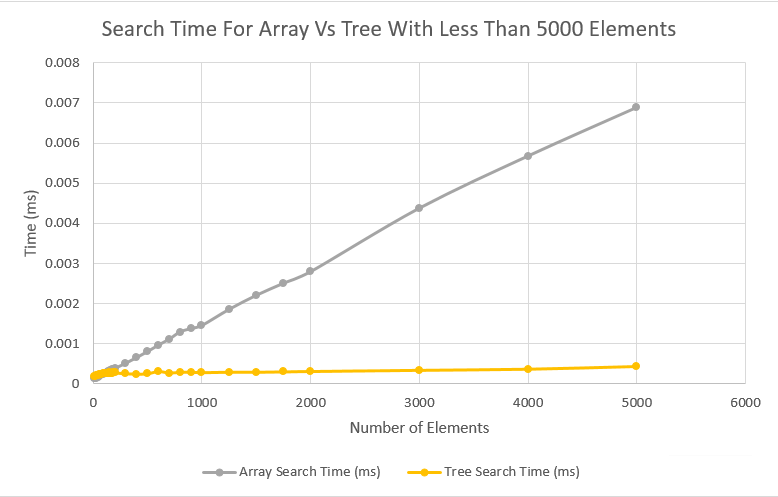
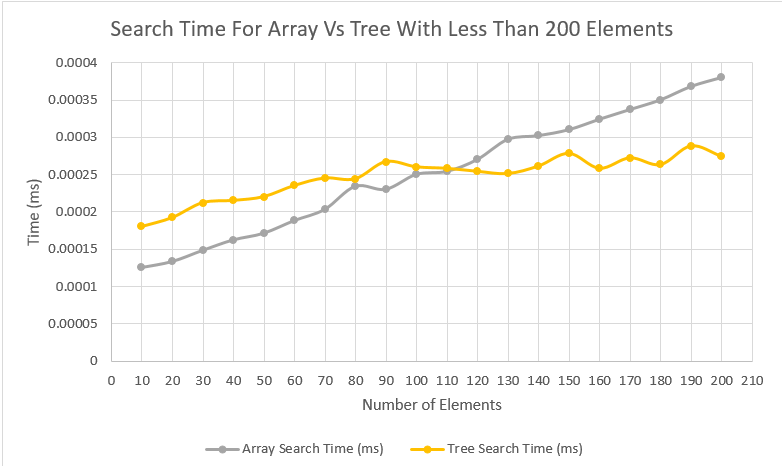
The first graph clearly demonstrates the greatly increased scalability of the red-black trees over standard arrays. You can the that the red-black trees, which scale logarithmically with size, quickly become much faster than arrays, which scale linearly, as more elements are added to the structures. The second graph shows a closeup of the data for structures of less than 200 elements and clearly shows the point where the logarithmic scaling tree search times level off and surpass the speed of the array searches.
It felt pretty good to finally see my trees fully functional and to watch them totally blow away the arrays and vectors I’ve been using up until now.